
AP计算机科学A:计算机科学
学习AP计算机科学A的概念,示例问题和解释


例子问题
例子问题1:标准操作和算法
考虑下面的代码:
公共静态类BTNode {
PARSE_IN = 1;
PARSE_PRE = 2;
PARSE_POST = 3;
字符串名称;
BTNode lPointer rPointer;
public BTNode(字符串){
name = s;
lPointer = rPointer = null;
}
public void insert(字符串){
插入(s);
}
私有静态void insert(BTNode节点,字符串){
int比较= s.compareTo(node.name);
If(比较< 0){
如果节点。lPointer != null) {
插入(node.lPointer s);
其他}{
节点。lPointer = new BTNode(s);
}
} else if(比较> 0){
如果节点。rPointer != null) {
插入(node.rPointer s);
其他}{
节点。rPointer = new BTNode(s);
}
}
}
public ArrayList
返回解析(这个,parseOrder);
}
private static ArrayList
ArrayList
If (node == null) {
返回(retVal);
}
ArrayList
ArrayList
if(parseOrder == PARSE_PRE) {
retVal.add (node.name);
retVal.addAll (leftList);
retVal.addAll (rightList);
} else if (parseOrder == PARSE_POST) {
retVal.addAll (leftList);
retVal.addAll (rightList);
retVal.add (node.name);
其他}{
retVal.addAll (leftList);
retVal.add (node.name);
retVal.addAll (rightList);
}
返回retVal;
}
}
public static void main(字符串[]args) {
String[]的名字= {" Hervaeus”、“彼得Auriol”、“Guiral”,“费利克斯”,“紫色”,“劳拉”,“Yippy”、“Yiiiipppy”、“阿克顿”、“皮尔斯”,“贝蒂”};
BTNode节点=新的BTNode(名称[0]);
For (int I = 1;我< names.length;我+ +){
node.insert(名称[我]);
}
ArrayList
for(字符串s: traversedNames) {
System.out.println(年代);
}
}
这个方法的输出是什么?
阿克顿
贝蒂
费利克斯
Guiral
Hervaeus
莱拉
萝拉
彼得Auriol
皮尔斯
Yiiiipppy
Yippy
彼得Auriol
Hervaeus
Guiral
阿克顿
贝蒂
费利克斯
莱拉
萝拉
Yippy
皮尔斯
Yiiiipppy
贝蒂
阿克顿
费利克斯
Guiral
萝拉
莱拉
皮尔斯
Yiiiipppy
Yippy
彼得Auriol
Hervaeus
BTNode中的递归错误。
Hervaeus
Guiral
费利克斯
阿克顿
贝蒂
彼得Auriol
莱拉
萝拉
Yippy
Yiiiipppy
皮尔斯
阿克顿
贝蒂
费利克斯
Guiral
Hervaeus
莱拉
萝拉
彼得Auriol
皮尔斯
Yiiiipppy
Yippy
所给出的代码是二叉树的标准实现,其中包含一个插入和一个解析方法。现在,您可以只关注解析逻辑,特别是将为指示符值PARSE_IN调用的逻辑。(注意,这只是在其他的解析方法的。这是一个“catch all”/ default,以防给出错误的解析顺序值。)
retVal.addAll (leftList);
retVal.add (node.name);
retVal.addAll (rightList);
这只是基于插入的标准二叉树解析样式。较小的项位于当前节点的左侧,较大的项位于当前节点的右侧。因此,你有:
所有较小值的列表+当前值+所有较大值的列表
递归地,这将以一个有序列表结束,这正是您所需要的。
例子问题1:遍历
考虑以下代码:
进口java.util.ArrayList;
MethodClass5 {
公共静态类BTNode {
PARSE_IN = 1;
PARSE_PRE = 2;
PARSE_POST = 3;
字符串名称;
BTNode lPointer rPointer;
public BTNode(字符串){
name = s;
lPointer = rPointer = null;
}
public void insert(字符串){
插入(s);
}
私有静态void insert(BTNode节点,字符串){
int比较= s.compareTo(node.name);
If(比较< 0){
如果节点。lPointer != null) {
插入(node.lPointer s);
其他}{
节点。lPointer = new BTNode(s);
}
} else if(比较> 0){
如果节点。rPointer != null) {
插入(node.rPointer s);
其他}{
节点。rPointer = new BTNode(s);
}
}
}
public ArrayList
返回解析(这个,parseOrder);
}
private static ArrayList
ArrayList
If (node == null) {
返回(retVal);
}
ArrayList
ArrayList
if(parseOrder == PARSE_PRE) {
retVal.add (node.name);
retVal.addAll (leftList);
retVal.addAll (rightList);
} else if (parseOrder == PARSE_POST) {
retVal.addAll (leftList);
retVal.addAll (rightList);
retVal.add (node.name);
其他}{
retVal.addAll (leftList);
retVal.add (node.name);
retVal.addAll (rightList);
}
返回retVal;
}
}
public static void main(字符串[]args) {
String[] names = {"Thomas Aquinas","Thomas Cajetan","Thomas Prufer","Thomas the Tank Engine","Thomas the breadeater "};
BTNode节点=新的BTNode(名称[0]);
For (int I = 1;我< names.length;我+ +){
node.insert(名称[我]);
}
ArrayList
for(字符串s: traversedNames) {
System.out.println(年代);
}
}
}
的输出是什么主要以上方法?
托马斯·阿奎那
托马斯Cajetan
托马斯Prufer
托马斯Bread-Eater
坦克发动机托马斯
坦克发动机托马斯
托马斯Prufer
托马斯Bread-Eater
托马斯·阿奎那
托马斯Cajetan
托马斯·阿奎那
坦克发动机托马斯
托马斯Prufer
托马斯Bread-Eater
托马斯Cajetan
托马斯Bread-Eater
坦克发动机托马斯
托马斯Prufer
托马斯Cajetan
托马斯·阿奎那
托马斯Bread-Eater
托马斯·阿奎那
坦克发动机托马斯
托马斯Prufer
托马斯Cajetan
托马斯Bread-Eater
坦克发动机托马斯
托马斯Prufer
托马斯Cajetan
托马斯·阿奎那
这段代码是二叉树类的标准实现。我们要打的电话主要用于按修复后的顺序解析树(遍历它)。这意味着我们总是先看每个节点的左边,然后看右边,最后看我们所处的值。然而,该树是不平衡的,因此解析将比其他任何方法做更多的正确遍历。请参阅以下插入顺序:
步骤1:

步骤2:

步骤3:
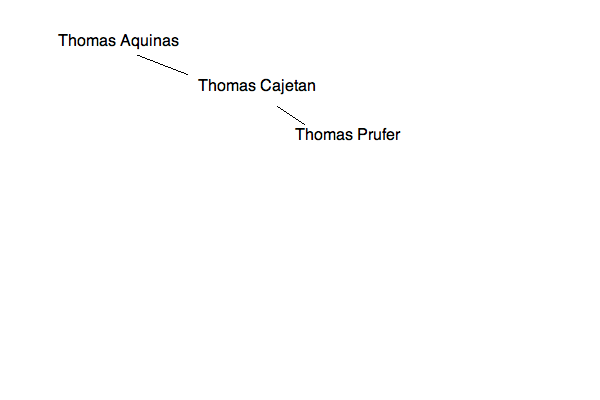
步骤4:
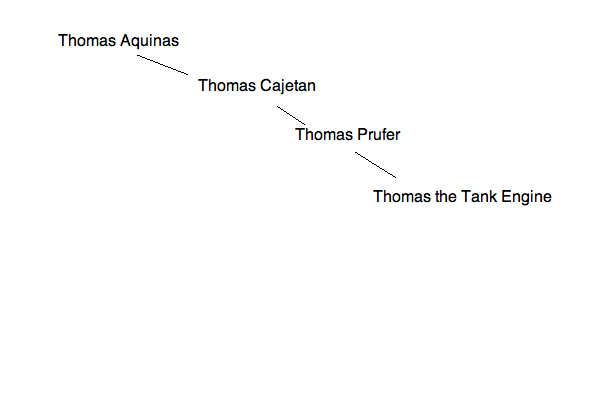
步骤5:
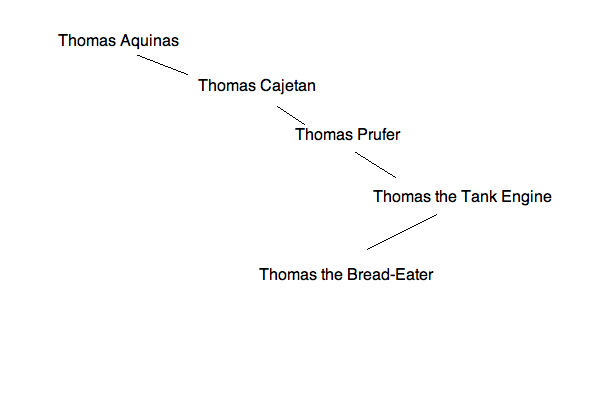
现在,你的遍历路径看起来像这样:
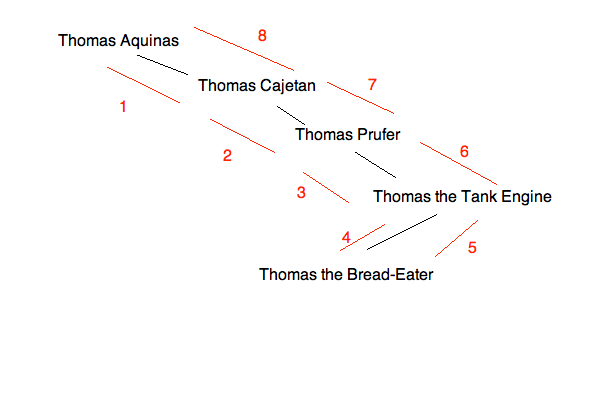
有趣的是,这意味着您最终将得到一个顺序相反的列表。这只是给定数据的情况,因为它碰巧被插入了。
例子问题1:计算机科学
复发定义如下:公共int递归(int x)
{
If (x <= 1)
{
返回1;
}
其他的
{
Return x + recurur (x/2);
}
复发在以下声明中调用?Int num = repeat (6);
3.
4
1
2
5
3.
第一个调用在声明中。因为6 > 1,它调用复发总共是2个。
接下来,它调用复发(6/2).因为3 > 1,它调用复发再一次,总共是3个。
接下来,它调用复发(3/2).因为这是整数除法,它的值是复发(1).
因为1 <= 1,它不调用复发所以总调用次数是3。
例子问题1:遍历
以下哪段代码执行定义为的数组的5个元素的乘法:
Int [][] vals = new Int [50][100];
假定数组已正确初始化并填充了值。
For (int I = 0;I < vals.length;i++) {
瓦尔斯[我]* = 5;
}
For (int I = 0;I < vals.length;i++) {
For (int j = 0;j < vals[我]. length;j + +) {
瓦尔斯[j] [j] * = 5;
}
}
For (int I = 0;I < vals.length;i++) {
For (int j = 0;j < vals.length;j + +) {
瓦尔斯[我][j] * = 5;
}
}
For (int I = 0;I < vals.length;i++) {
瓦尔斯[我][0…99] * = 5;
}
For (int I = 0;I < vals.length;i++) {
For (int j = 0;j < vals[我]. length;j + +) {
瓦尔斯[我][j] * = 5;
}
}
For (int I = 0;I < vals.length;i++) {
For (int j = 0;j < vals[我]. length;j + +) {
瓦尔斯[我][j] * = 5;
}
}
我们在这个问题中寻找的是一个二维数组的标准遍历。当您这样做时,您需要确保进行了遍历这两个行和列。为了做到这一点,你首先必须建立一个像这样的循环:
For (int I = 0;I < vals.length;i++){…
的价值vals.length表示二维数组的行数。
现在,对于每一行,你有一定数量的列。(2D数组类似于“数组的数组”。)因此,对于每一行,你需要遍历该行的整个列集:
For (int j = 0;j < vals[我]. length;j + +){…
注意,所有错误的问题都没有使用val [i]。这样的长度。因此,它们都不能正确地遍历数组的两个维度。
例子问题1:标准操作和算法
树的遍历
给定以下树形结构:
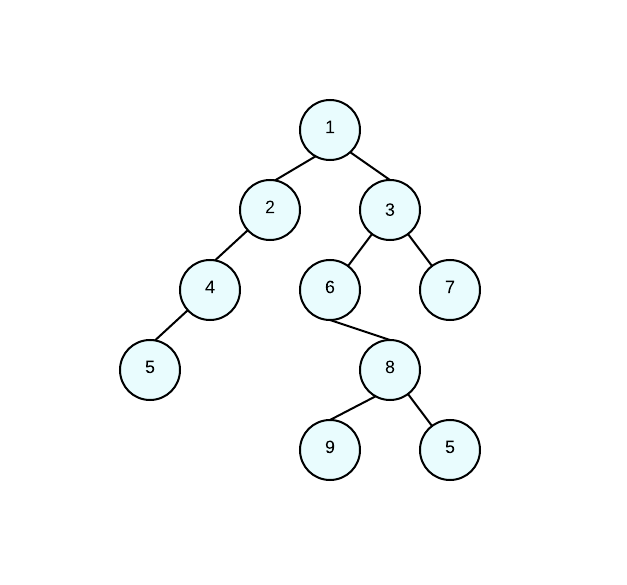
树的预先遍历是什么?
1 2 3 4 6 7 5 8 9 5
1 2 3 4 5 5 6 7 8 9
1 2 4 5 3 6 8 9 5 7
5 4 2 1 3 6 7 8 9 5
1 2 4 5 3 6 8 9 5 7
当预购遍历完成后,将执行以下操作:
1.根
2.左子
3.右子
因此,从根节点(1)开始,我们到左节点(2)。然而,这个节点是其他节点的根/父节点,所以我们再次向左(4)。那个节点是父/根节点,所以我们向左(5)。现在是时候向右移动了;然而,只有节点1右子,所以要我们土地的权利(3),节点的父/根更多的孩子所以我们向左(6),节点6没有留下孩子,但它确实有权利我们(8)。8有左子节点遍历(9)和(5)。我们将正确的完成遍历的三(7)。这是一个相当复杂的例子;但是,请确保您可以正确地遍历树。
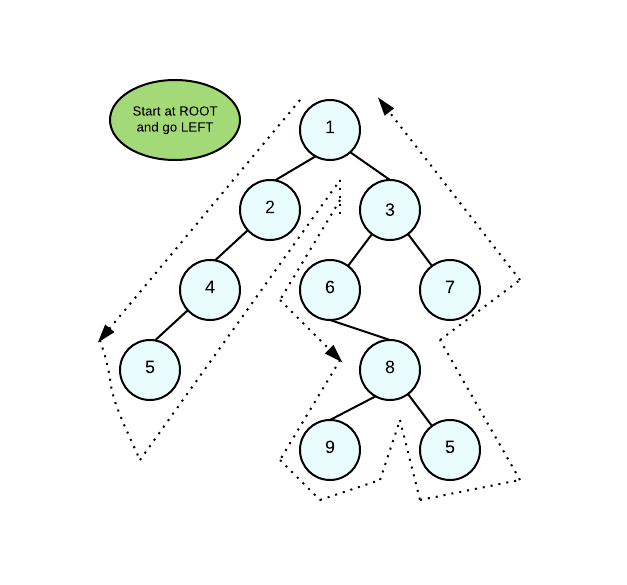
在上面的图像中,你可以看到预先顺序遍历的方法。首先是树根,然后是左边的树,然后是右边的树。确保如果你按照上面的图片引导自己,你不会重复你已经遍历过的节点。理解算法是关键。
例子问题1:遍历
遍历并打印出这个列表
List
integers.add (1);
integers.add (2);
integers.add (3);
For (int I = 0;我< integers.size () 1;我+ +){
System.out.println(整数[我]);
}
System.out.println (integers.get (0));
System.out.println (integers.get (1));
System.out.println (integers.get (2));
For (int I = 0;我< integers.size () 1;我+ +){
System.out.println (integers.get (i));
}
For (int I = 0;我< integers.length-1;我+ +){
System.out.println (integers.get (i));
}
For (int I = 0;我< integers.size () 1;我+ +){
System.out.println (integers.get (i));
}
使用for循环遍历列表。.size()方法用于列表,与用于数组的.length方法相反。.get()方法用于列表,而不是访问数组的索引。
例子问题1:标准操作和算法
考虑下面的代码:
公共静态类BTNode {
PARSE_IN = 1;
PARSE_PRE = 2;
PARSE_POST = 3;
字符串名称;
BTNode lPointer rPointer;
public BTNode(字符串){
name = s;
lPointer = rPointer = null;
}
public void insert(字符串){
插入(s);
}
私有静态void insert(BTNode节点,字符串){
int比较= s.compareTo(node.name);
If(比较< 0){
如果节点。lPointer != null) {
插入(node.lPointer s);
其他}{
节点。lPointer = new BTNode(s);
}
} else if(比较> 0){
如果节点。rPointer != null) {
插入(node.rPointer s);
其他}{
节点。rPointer = new BTNode(s);
}
}
}
public ArrayList
返回解析(这个,parseOrder);
}
private static ArrayList
ArrayList
If (node == null) {
返回(retVal);
}
ArrayList
ArrayList
if(parseOrder == PARSE_PRE) {
retVal.add (node.name);
retVal.addAll (leftList);
retVal.addAll (rightList);
} else if (parseOrder == PARSE_POST) {
retVal.addAll (leftList);
retVal.addAll (rightList);
retVal.add (node.name);
其他}{
retVal.addAll (leftList);
retVal.add (node.name);
retVal.addAll (rightList);
}
返回retVal;
}
}
public static void main(字符串[]args) {
String[]的名字= {" Hervaeus”、“彼得Auriol”、“Guiral”,“费利克斯”,“紫色”,“劳拉”,“Yippy”、“Yiiiipppy”、“阿克顿”、“皮尔斯”,“贝蒂”};
BTNode节点=新的BTNode(名称[0]);
For (int I = 1;我< names.length;我+ +){
node.insert(名称[我]);
}
ArrayList
for(字符串s: traversedNames) {
System.out.println(年代);
}
}
这个方法的输出是什么?
阿克顿
贝蒂
费利克斯
Guiral
Hervaeus
莱拉
萝拉
彼得Auriol
皮尔斯
Yiiiipppy
Yippy
彼得Auriol
Hervaeus
Guiral
阿克顿
贝蒂
费利克斯
莱拉
萝拉
Yippy
皮尔斯
Yiiiipppy
贝蒂
阿克顿
费利克斯
Guiral
萝拉
莱拉
皮尔斯
Yiiiipppy
Yippy
彼得Auriol
Hervaeus
BTNode中的递归错误。
Hervaeus
Guiral
费利克斯
阿克顿
贝蒂
彼得Auriol
莱拉
萝拉
Yippy
Yiiiipppy
皮尔斯
阿克顿
贝蒂
费利克斯
Guiral
Hervaeus
莱拉
萝拉
彼得Auriol
皮尔斯
Yiiiipppy
Yippy
所给出的代码是二叉树的标准实现,其中包含一个插入和一个解析方法。现在,您可以只关注解析逻辑,特别是将为指示符值PARSE_IN调用的逻辑。(注意,这只是在其他的解析方法的。这是一个“catch all”/ default,以防给出错误的解析顺序值。)
retVal.addAll (leftList);
retVal.add (node.name);
retVal.addAll (rightList);
这只是基于插入的标准二叉树解析样式。较小的项位于当前节点的左侧,较大的项位于当前节点的右侧。因此,你有:
所有较小值的列表+当前值+所有较大值的列表
递归地,这将以一个有序列表结束,这正是您所需要的。
例子问题1:遍历
考虑以下代码:
进口java.util.ArrayList;
MethodClass5 {
公共静态类BTNode {
PARSE_IN = 1;
PARSE_PRE = 2;
PARSE_POST = 3;
字符串名称;
BTNode lPointer rPointer;
public BTNode(字符串){
name = s;
lPointer = rPointer = null;
}
public void insert(字符串){
插入(s);
}
私有静态void insert(BTNode节点,字符串){
int比较= s.compareTo(node.name);
If(比较< 0){
如果节点。lPointer != null) {
插入(node.lPointer s);
其他}{
节点。lPointer = new BTNode(s);
}
} else if(比较> 0){
如果节点。rPointer != null) {
插入(node.rPointer s);
其他}{
节点。rPointer = new BTNode(s);
}
}
}
public ArrayList
返回解析(这个,parseOrder);
}
private static ArrayList
ArrayList
If (node == null) {
返回(retVal);
}
ArrayList
ArrayList
if(parseOrder == PARSE_PRE) {
retVal.add (node.name);
retVal.addAll (leftList);
retVal.addAll (rightList);
} else if (parseOrder == PARSE_POST) {
retVal.addAll (leftList);
retVal.addAll (rightList);
retVal.add (node.name);
其他}{
retVal.addAll (leftList);
retVal.add (node.name);
retVal.addAll (rightList);
}
返回retVal;
}
}
public static void main(字符串[]args) {
String[] names = {"Thomas Aquinas","Thomas Cajetan","Thomas Prufer","Thomas the Tank Engine","Thomas the breadeater "};
BTNode节点=新的BTNode(名称[0]);
For (int I = 1;我< names.length;我+ +){
node.insert(名称[我]);
}
ArrayList
for(字符串s: traversedNames) {
System.out.println(年代);
}
}
}
的输出是什么主要以上方法?
托马斯·阿奎那
托马斯Cajetan
托马斯Prufer
托马斯Bread-Eater
坦克发动机托马斯
坦克发动机托马斯
托马斯Prufer
托马斯Bread-Eater
托马斯·阿奎那
托马斯Cajetan
托马斯·阿奎那
坦克发动机托马斯
托马斯Prufer
托马斯Bread-Eater
托马斯Cajetan
托马斯Bread-Eater
坦克发动机托马斯
托马斯Prufer
托马斯Cajetan
托马斯·阿奎那
托马斯Bread-Eater
托马斯·阿奎那
坦克发动机托马斯
托马斯Prufer
托马斯Cajetan
托马斯Bread-Eater
坦克发动机托马斯
托马斯Prufer
托马斯Cajetan
托马斯·阿奎那
这段代码是二叉树类的标准实现。我们要打的电话主要用于按修复后的顺序解析树(遍历它)。这意味着我们总是先看每个节点的左边,然后看右边,最后看我们所处的值。然而,该树是不平衡的,因此解析将比其他任何方法做更多的正确遍历。请参阅以下插入顺序:
步骤1:
步骤2:
步骤3:
步骤4:
步骤5:
现在,你的遍历路径看起来像这样:
有趣的是,这意味着您最终将得到一个顺序相反的列表。这只是给定数据的情况,因为它碰巧被插入了。
例子问题1:计算机科学
复发定义如下:公共int递归(int x)
{
If (x <= 1)
{
返回1;
}
其他的
{
Return x + recurur (x/2);
}
复发在以下声明中调用?Int num = repeat (6);
3.
4
1
2
5
3.
第一个调用在声明中。因为6 > 1,它调用复发总共是2个。
接下来,它调用复发(6/2).因为3 > 1,它调用复发再一次,总共是3个。
接下来,它调用复发(3/2).因为这是整数除法,它的值是复发(1).
因为1 <= 1,它不调用复发所以总调用次数是3。
例子问题1:遍历
以下哪段代码执行定义为的数组的5个元素的乘法:
Int [][] vals = new Int [50][100];
假定数组已正确初始化并填充了值。
For (int I = 0;I < vals.length;i++) {
瓦尔斯[我]* = 5;
}
For (int I = 0;I < vals.length;i++) {
For (int j = 0;j < vals[我]. length;j + +) {
瓦尔斯[j] [j] * = 5;
}
}
For (int I = 0;I < vals.length;i++) {
For (int j = 0;j < vals.length;j + +) {
瓦尔斯[我][j] * = 5;
}
}
For (int I = 0;I < vals.length;i++) {
瓦尔斯[我][0…99] * = 5;
}
For (int I = 0;I < vals.length;i++) {
For (int j = 0;j < vals[我]. length;j + +) {
瓦尔斯[我][j] * = 5;
}
}
For (int I = 0;I < vals.length;i++) {
For (int j = 0;j < vals[我]. length;j + +) {
瓦尔斯[我][j] * = 5;
}
}
我们在这个问题中寻找的是一个二维数组的标准遍历。当您这样做时,您需要确保进行了遍历这两个行和列。为了做到这一点,你首先必须建立一个像这样的循环:
For (int I = 0;I < vals.length;i++){…
的价值vals.length表示二维数组的行数。
现在,对于每一行,你有一定数量的列。(2D数组类似于“数组的数组”。)因此,对于每一行,你需要遍历该行的整个列集:
For (int j = 0;j < vals[我]. length;j + +){…
注意,所有错误的问题都没有使用val [i]。这样的长度。因此,它们都不能正确地遍历数组的两个维度。




